DSA - 栈和队列
准备期中做的笔记,第四章栈和队列
今天买了一瓶番茄乌梅洛神饮,建议去掉番茄,真难喝我再也不买这种黑暗料理了,喝了满嘴都是番茄味,不是酸味就是那种果蔬的健康的味道,真让人作呕。但是陈皮或者乌梅泡洛神花还是很好喝的。
栈和队列
栈
栈:只能在栈顶插入删除,栈底为盲端。后进先出。
调用栈:函数递归时维护一个栈记录先前调用的函数参数。递归算法所需空间取决于递归深度而非实例总数
尾递归优化:函数最多自我调用一次,唯一的调用恰好位于 return 之前。显式维护调用栈,将递归算法改写成迭代版本。
一旦抵达递归基就会触发一连串 return,调用栈连续 pop,瞬间清空,可以复写老帧。
头递归:例子:短除法
1 | 0001 void convert( uint64_t n, int base ) { //进制转换(递归版) |
1 | 0001 void convert( uint64_t n, int base ) { //进制转换(迭代版) |
括号匹配与表达式求值
剥洋葱。消去一对紧邻的括号不影响表达式匹配。用栈记录已经扫描到但等待处理的部分。
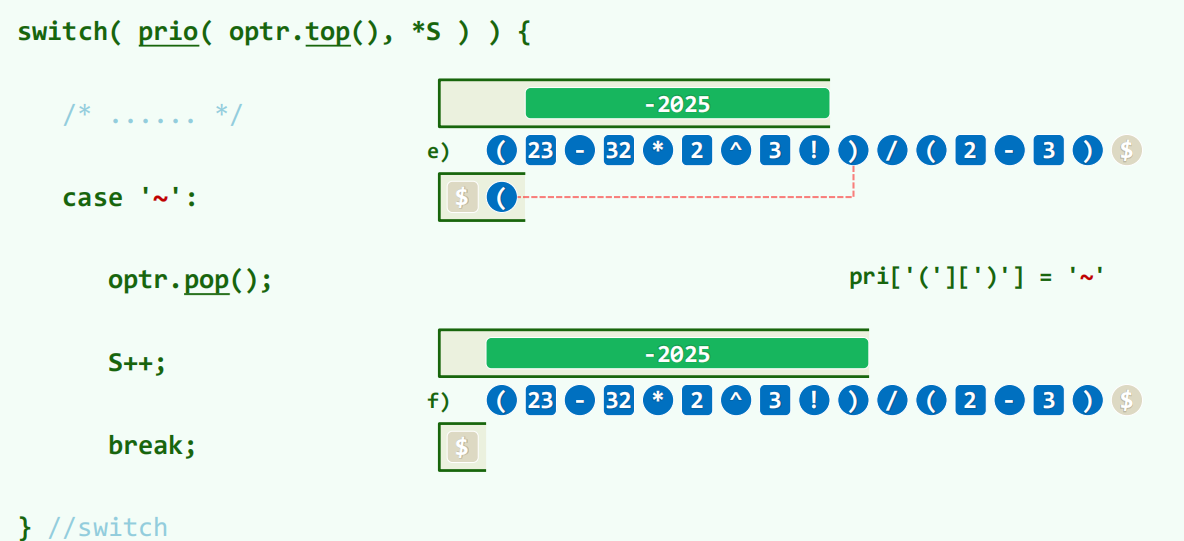
多类括号:左括号无论哪种一律进栈,右括号必须与栈顶左括号同类。最终空栈。
优先级高的局部执行计算并以数值替代,相当于洋葱的心。
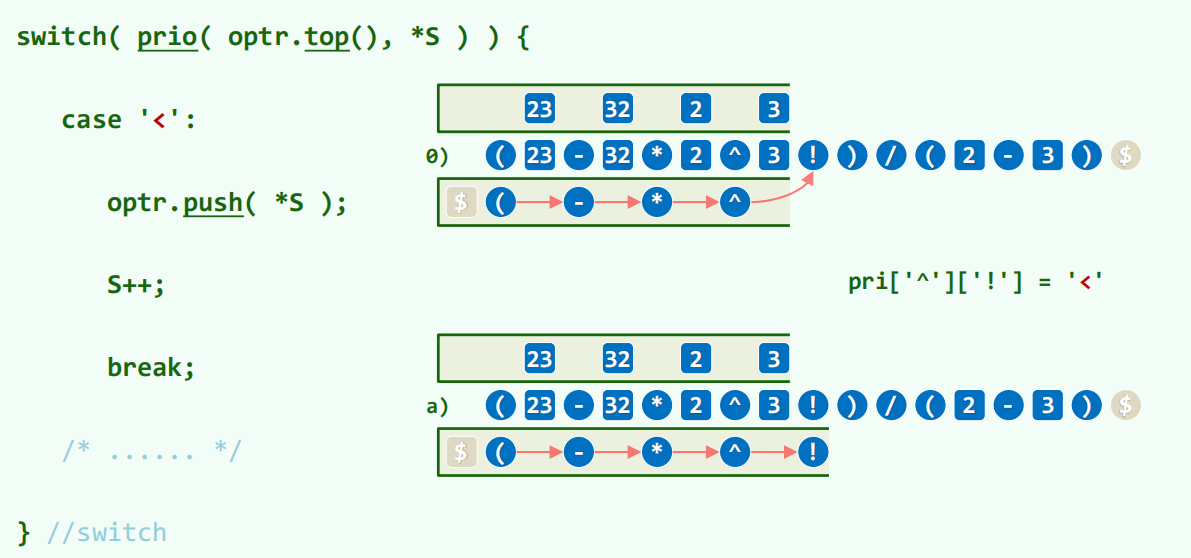
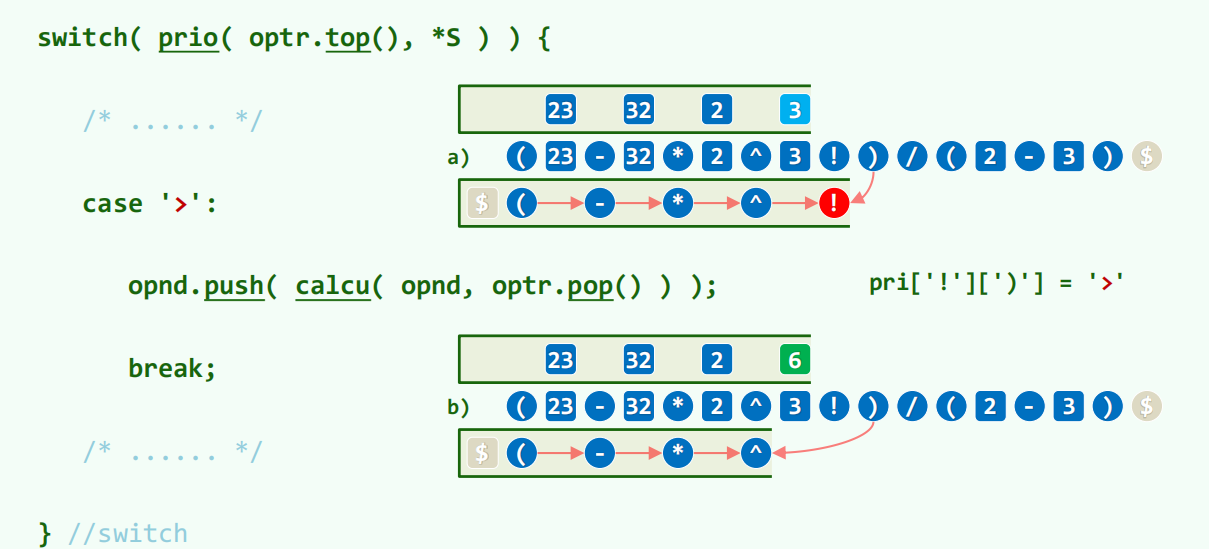
栈内运算符的优先级渐次升高,栈顶部分能否运算取决于局部栈顶的相对优先级。比较栈顶运算符和当前运算符。
运算符和运算数分开用两个栈存储。一次扫描,分别压栈。
左括号在栈顶比当前运算符小,作为伪栈底;左括号在当前位置比栈顶运算符大,保证前面所有计算暂停。
右括号疯狂触发大于逻辑,一直触发计算,直到遇见左括号。
逆波兰表达式:需要额外引入起分隔作用的空格,但是没有括号。未必比中缀式更短。
只需要一个栈就可以完成,把运算数压栈,遇到算符就取出两个算出结果压回去,直到只剩最后一个。
中缀式转 RPN:如果当前是运算数直接接入 RPN;如果是算符且可以立即执行接入 RPN。其余和表达式求值逻辑相同。
栈混洗:
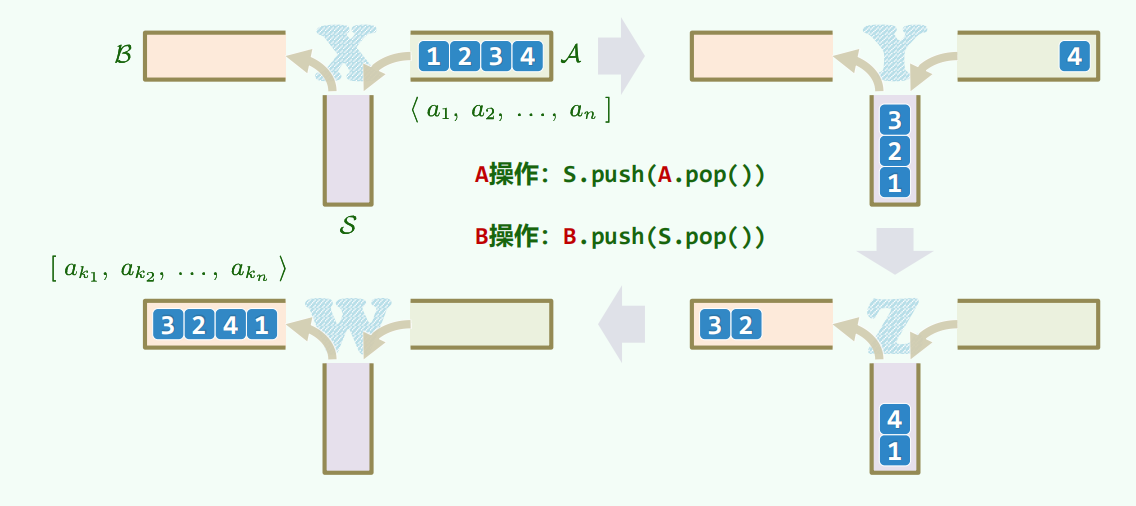
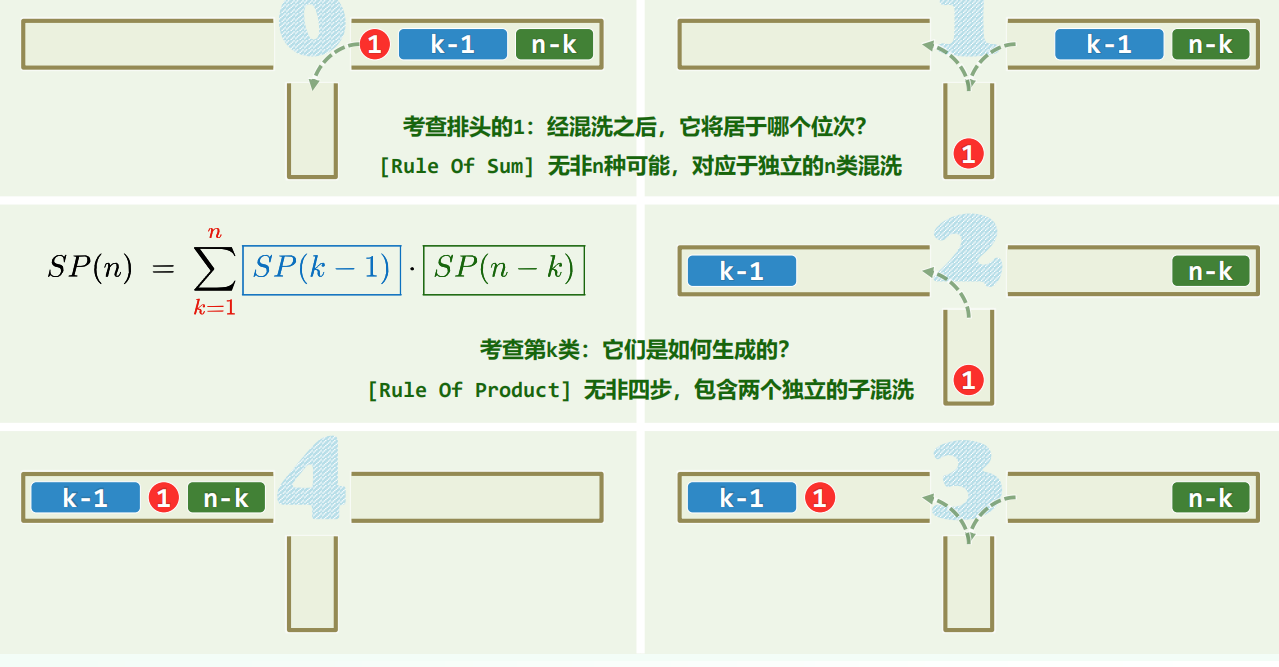
卡特兰数。
括号序列匹配,二叉树个数,都可以转化为栈混洗。
队列:先进先出。
可以由两个栈模拟。
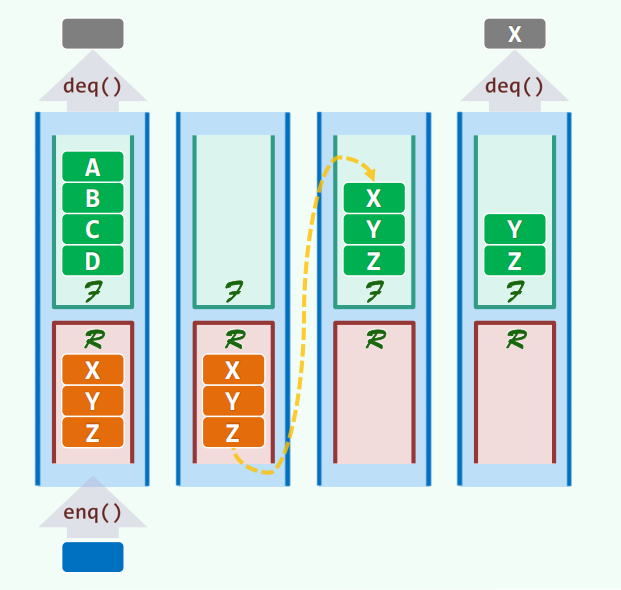
1 | def Q.enqueue(e) |
记账法:每个元素分配 4 块钱。每个元素必然经历入栈 R(1 块钱),出栈 R(1 块钱),入栈 F(1 块钱),出栈 F(1 块钱),于是总共分配 4n = O (n),也就是说总时间复杂度 O (n)
向量去重算法的记账法:
1 | 0001 template <typename T> void Vector<T>::dedup() { //O(n^2) |
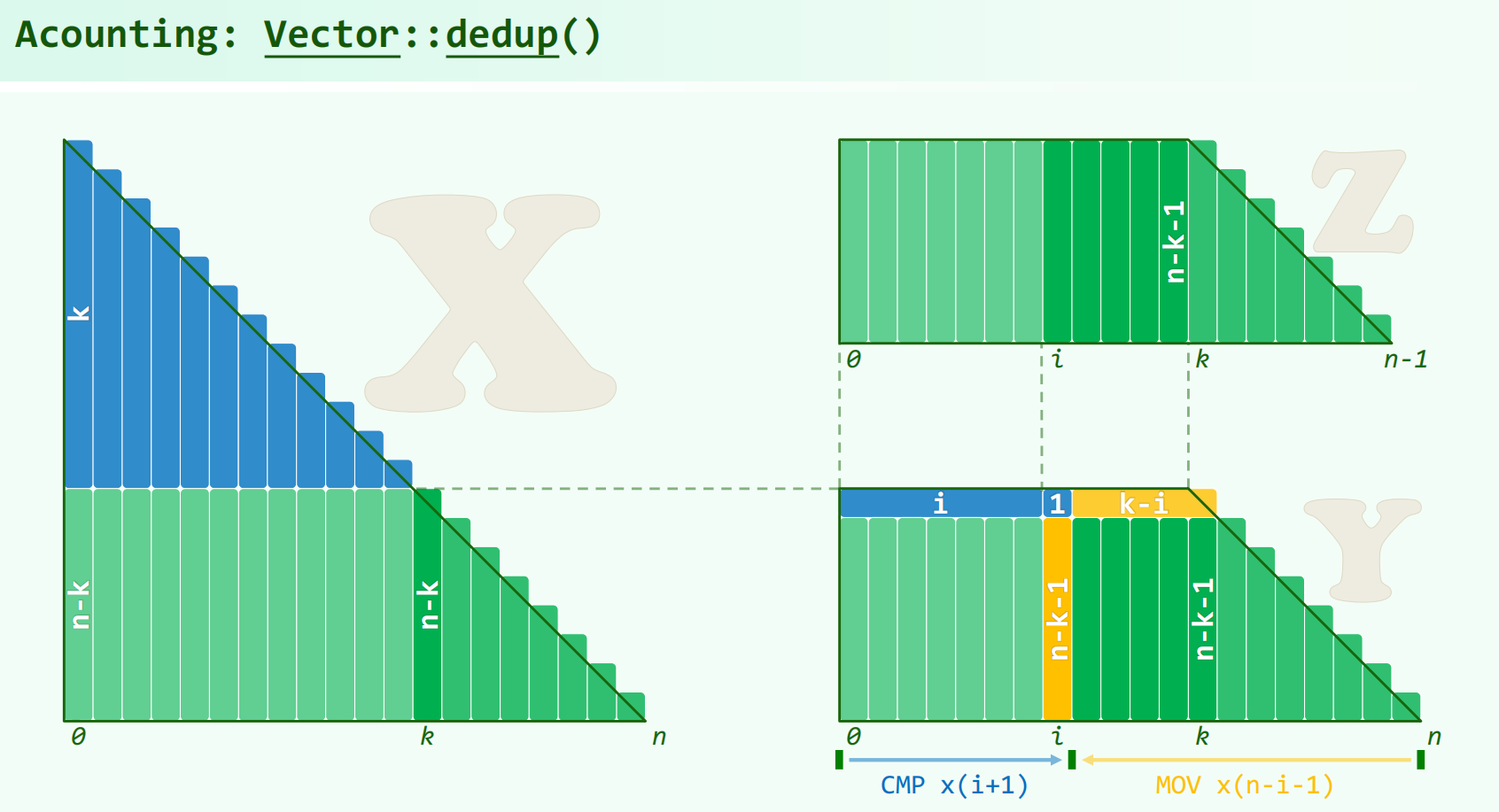
每个元素预先配发 n-i 块钱,比较:由前面的被比较的元素支付,每个支付 1 元;移动:从 i + 1 到 k 由被访问的元素支付,从 k + 1 到 n 由第 i 个,也就是被删除的元素支付。可使得考查到 [k] 时候还剩 n 个元素,前面 [0,k] 个元素每个人 n-k 块钱。
聚合法:考虑 d 次出队操作和 e 次入队操作,共有 d 个元素走完生命周期共 4d 时间,剩余 (e-d) 个元素最坏发生 2 次入栈和 1 次出栈。总计 4d + 3 (e-d) 的时间,平摊到每次操作是 $\frac {d + 3e}{d + e}$ 次操作,故 O (n)
势能法:有些操作当前非常便宜,但是会积累未来的负担;有些操作非常昂贵,但消除了原先积累的债。
从每一步操作看,$A_k = T_k+\Delta \Phi$,平摊成本 = 实际成本(cpu 真正此时执行的操作)+ 势能变化(原先欠的债的改变)
定义 $\Phi_k=|R_k|-|F_k|$,入队:实际成本 1,势能变化 + 1,平摊 2;正常出队:实际成本 1,势能变化 + 1,平摊 2;倒腾出队:实际成本:2r + 1,势能变化 1-2r,平摊 2。
$\sum A_k=2n=T(n)+\Phi_n-\Phi_0>T(n)-n,T(n)<3n=O(n)$
向量去重:考查到第 [k] 个元素时已经剔除了个元素,前缀|后缀 =k-d|n-k,定义 $\Phi_k=(k-d)(n-k)$。
有重复:$T_k=|search|+|remove|=i+n-d-i=n-d,\Delta \Phi=(k-d)(n-k-1)-(k-d)(n-k)=d-k,A_k=n-k$
无重复,算出来也是 n-k
于是 T 总和是 n (n + 1)/2 = O (n2)
单调队列 / 单调栈
直方图最大矩形
直方图内的最大矩形的高度由内部最短的柱子决定。对每一根柱子考查它当作主导柱子,统计向左向右能走多远。只要算出每根柱子的左边界 sr 和右边界 tr 就能算出直方图最大矩形,需要扫描两遍。
扫描一遍的做法,维护一个递增的单调栈,对于新元素 r 压栈的时候,它可能需要剔除元素 k;k 的右边界就是 r,因为这是它在右侧遇到的第一个比自己小的元素;而 r 最后暴露出的栈顶就是它的左边界,因为这是左侧第一个比它小的元素。
1 | 0001 uint64_t mr_STACK( uint64_t H[], Rank n ) { //单趟扫描版 |
单调栈:
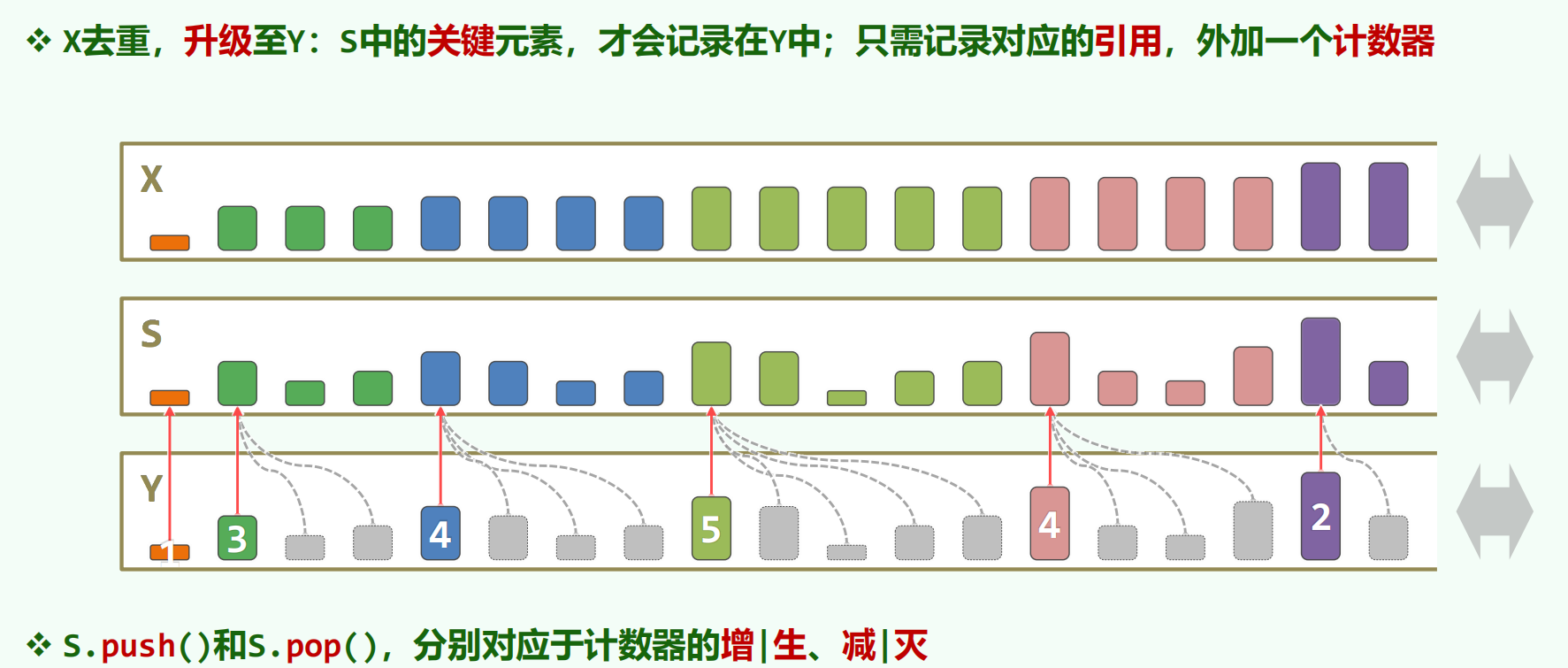
单调队列:每个元素一生进入一次出去一次,所以均摊 O (1)
