DSA - 树和二叉树
准备数据结构期中的复习笔记,第五章树和二叉树
树和二叉树
树
指定某一节点为根后,即是有根树。零度节点称叶子,其余为内部节点。
兄弟之间依据 ${r_1,r_2,…,r_d}$ 排序就是有序树
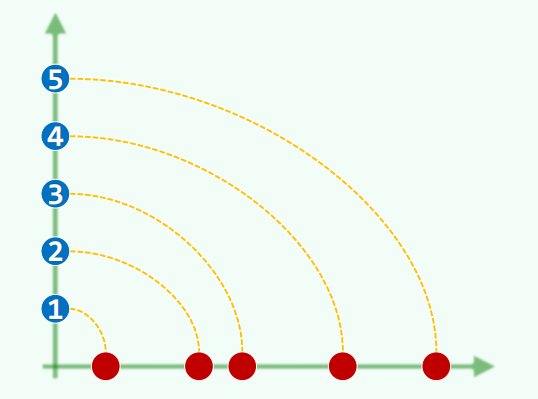
深度,层次:
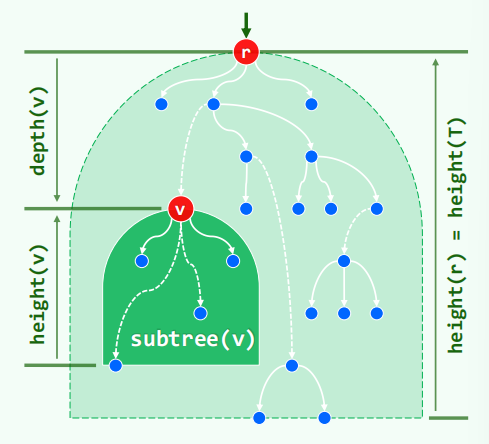
从任意祖先 r 出发,沿边逐代下溯可以抵达各级后代 v。路径的边数为路径长度。若 r 为全树的根,路径长度为 v 的深度。依照深度可以划分为 h + 1 类节点。所有节点的最大深度称为树的高度。空树高度 =-1。
节点高度 = 后代最大深度 - 自己深度 = 子树高度。
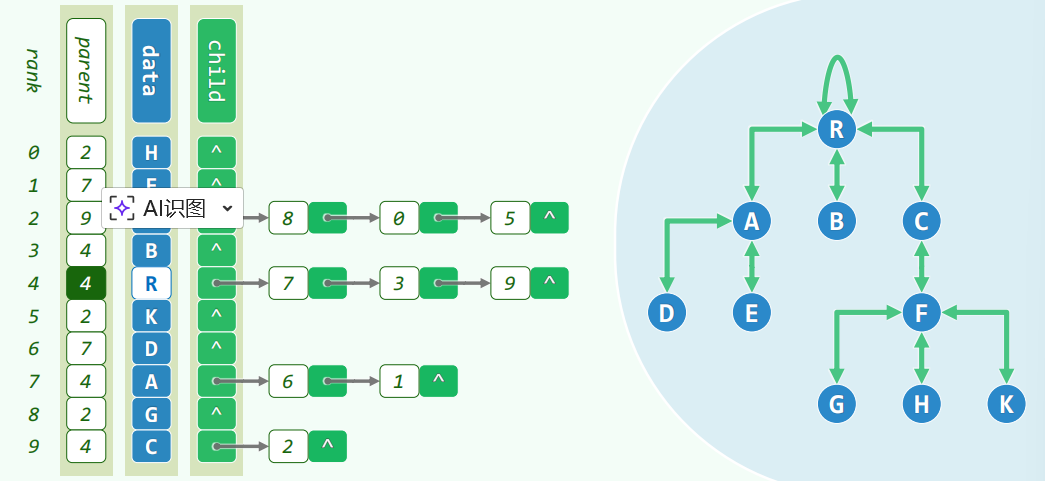
ADT 和实现
父节点 + 孩子节点实现,对每个节点都存储所有孩子的链表,以及父亲的下标。
二叉树性质
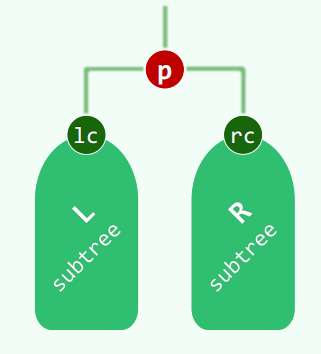
节点度数不超过 2。
对 lc、rc 来说 p 是左父亲和右父亲,对 p 来说 lc、rc 是左儿子和右儿子。
不含单分支节点的二叉树称为真二叉树。可以引入虚构外部节点实现真二叉树
描述多叉树:长子弟弟表示法。长子放左孩子,最大的弟弟放右孩子,递归处理
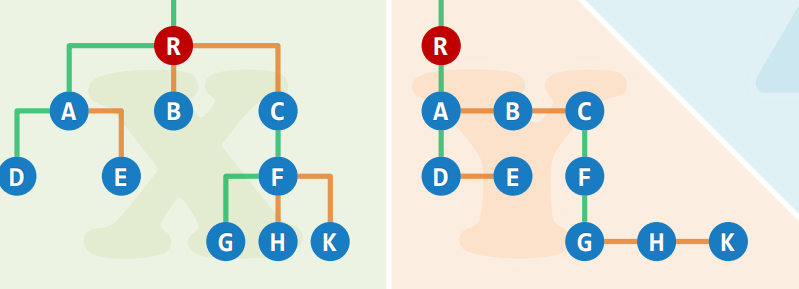
二叉树实现
1 | 0009 BinNode( T e, BNP<T> _p = nullptr, BNP<T> lc = nullptr, |
更新高度
1 | 0003 template <typename T> int BinNode<T>::updateHeight() //更新当前节点高度 |
优化:如果当前高度和更新之后的一样就退出循环,最好情况优化到 O (1)
接入和取出:
1 | 0001 template <typename T> //将S当作节点x的右子树接入,再将S置空 |
1 | 0001 template <typename T> BinTree<T> BinTree<T>::secede( BNP<T> x ) { //子树分离 |
遍历
前序、中序、后序遍历。

深复制
1 | 0001 template <typename T> BNP<T> clone( BNP<T> p, BNP<T> t ) { //深复制 |
迭代实现先序遍历:观察先序遍历的行走顺序
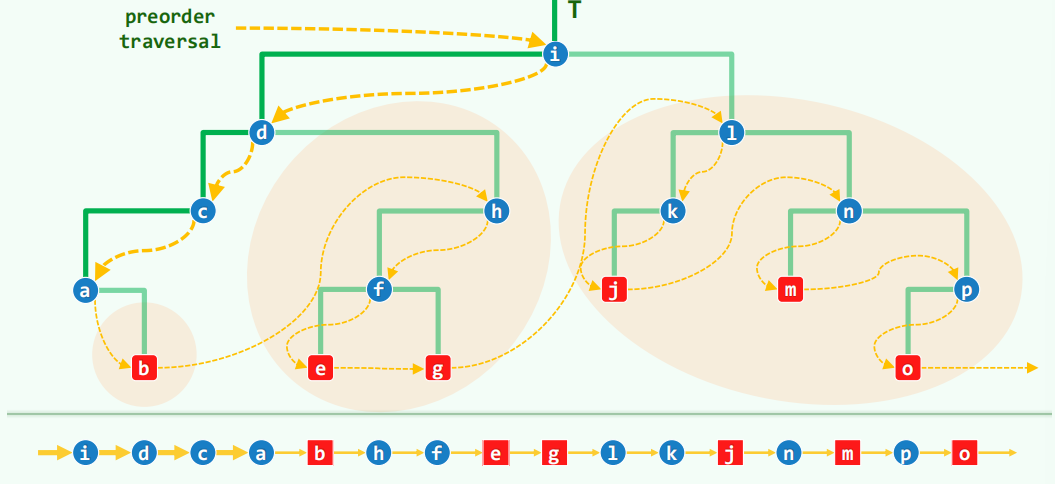
藤:起始于根的左侧通路,长子通路
先序遍历相当于自上而下访问藤上节点,再自下而上遍历各右子树。
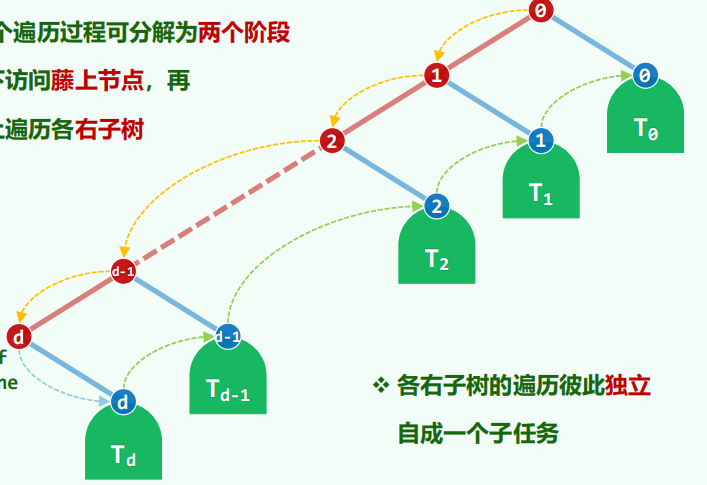
在访问藤的时候暂时不能访问右子树,需要暂存起来;右子树的遍历顺序和藤的访问顺序恰好相反。
1 | 0001 template <typename T, typename V> void preorder1( BNP<T> x, V& visit ) { |
单循环写法:每次弹出一个节点,先压左孩子,再压右孩子
摊还分析:只有右孩子才能且必须进栈。摊还至每个节点不超过 O (1)。
空间和高度相关。
迭代实现中序遍历:
沿藤分解,自底向上访问藤上节点,没有左节点就转向右孩子。继续遍历右子树。
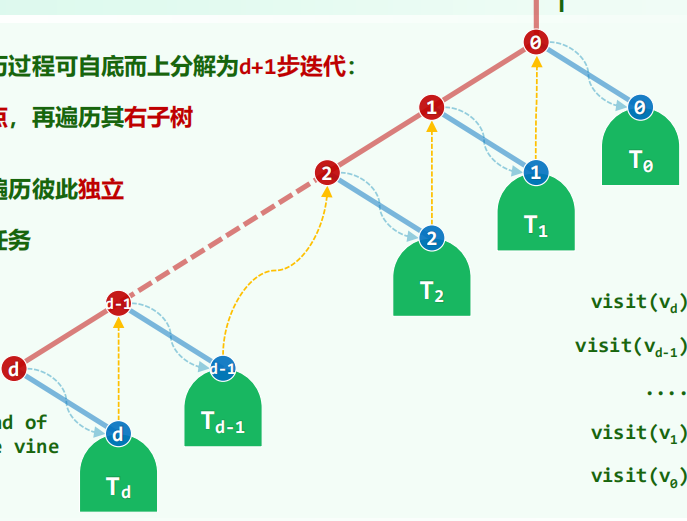
1 | 0001 template <typename T, typename V> void inorder1( BNP<T> x, V& visit ) { |
数学归纳:假设对规模不超过 n 的树成立,考查 n + 1, 根 = x,藤终点 = t,t 的右孩子 = y
先走到藤终点 t,访问,转向右子树 y,递归;返回再转向藤的右子树串,递归。对每个递归都能正确进行,且整个过程正确。
均摊分析:记账法
每个节点 3 块钱,分别支付 push (x) 和 pop (x)。尝试转向右子树的时候,如果右子树不是空树可以让右孩子支付;如果是空树这部分判断开销由 x 的第三块钱支付。
中序后继:
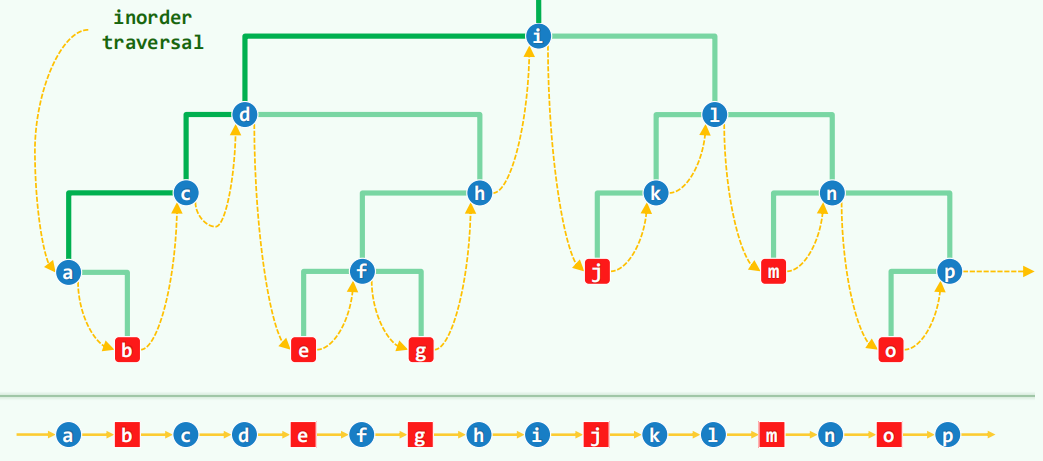
取决于是否有右子树:
有右子树,直接后继是右子树中藤的终点;
没有右子树,直接后继是 x 最低的左祖先(寻找以 x 为前驱的节点)
( 前序后继:有左孩子就是左孩子;没左孩子有右孩子就是右孩子;叶子节点找 x 最低的有右孩子的左祖先)
1 | 0001 template <typename T> BNP<T> eov( BNP<T> x ) { //End Of Vine |
统计所有遍历中 x 被赋值的次数记作 T (n):把所有的 eov 和 lla 操作打碎到每次递归
根节点 x 转向左子树,统计一次赋值
完成左子树的中序遍历
经过 lla 的最后一步回到 x,算在左子树里面。
访问 x
为查找 eov 转入右子树,算在右子树里面
完成右子树的中序遍历
最后一次 lla 的最后一步回到 x,统计一次赋值
T (n)=T (m)+T (n-m-1)+2, 线性
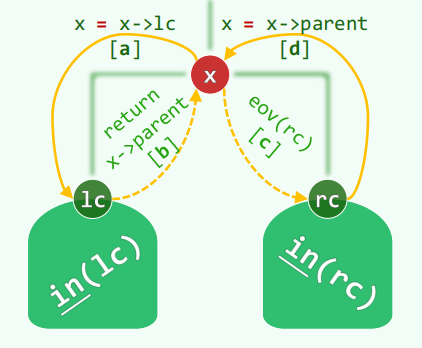
后序遍历迭代实现:
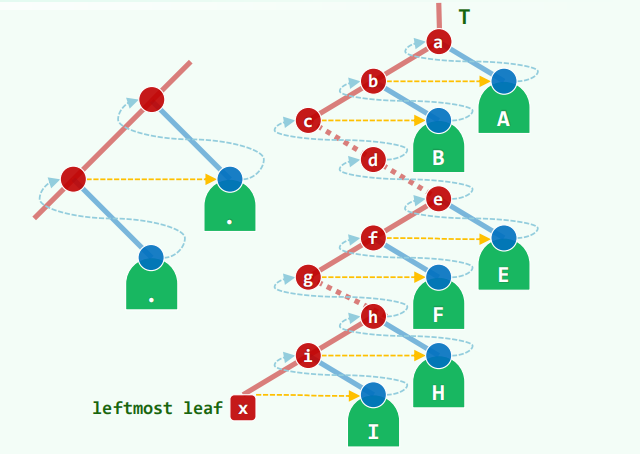
尽可能向左,左到不能再左才向右,直到全树最左的节点开始遍历。这样的路径设置为藤。
需要用栈记录藤。栈实际存储的是所有的藤。
变量实际记录刚刚访问的上一个节点,要考查下一步访问哪一个节点
右孩子也要被记录到栈里,而且先进后出。
1 | 0001 template <typename T> void gotoLeftmostLeaf( Stack<BNP<T>>& S ) { |
层次遍历:队列,对队头元素压入左右孩子。辅助队列的规模不会超过一层的元素个数。
由遍历重建树
先后 + 中:分治。
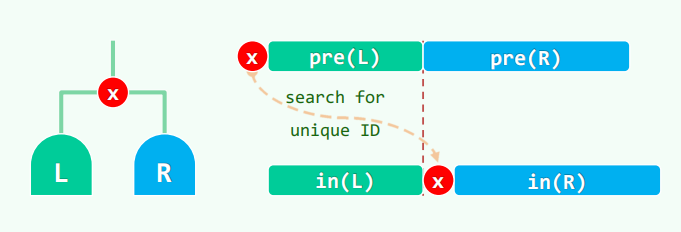
先序和后序不能重建,因为不知道每个 x 是不是没有右子树
先序后序可以还原真二叉树,对于根节点 x,先序中 x 后一个元素一定是左子树的根,后序中 x 的前一个元素一定是右子树的根。可以分治。
对于增强的序列,只需要单独先或后遍历就可以还原。
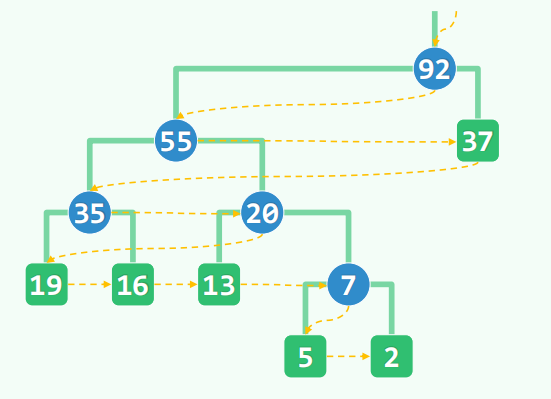
Huffman 树
while (F 中的树不止一棵)
取出频率最小的两棵树 T1,T2
合并成新树,以 T2,T1 为左右子树,权重为 T2 + T1
剩下唯一一棵树是一个最优编码树。
正确性:假设频率最小的字符 x,y 不是兄弟,可通过交换使得加权编码长度最小
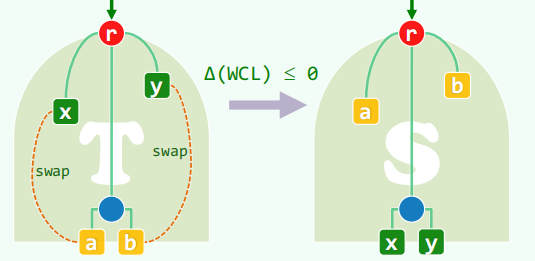
考查合并操作,合并 x,y = z 之后加权编码长度之差为 w (z)=w (x)+w (y)
且这个差距最小。
差距固定,则需要继续在 $\pi$ 树中找两个最小的节点合并,实现下一步的最小差距。
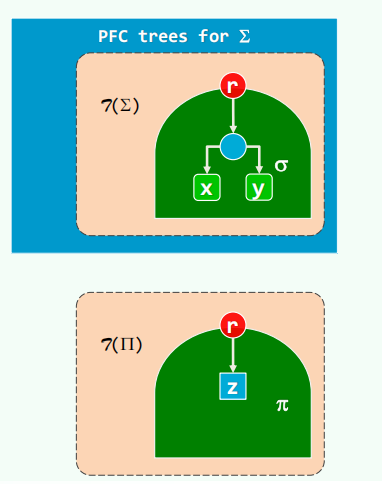
线性归约
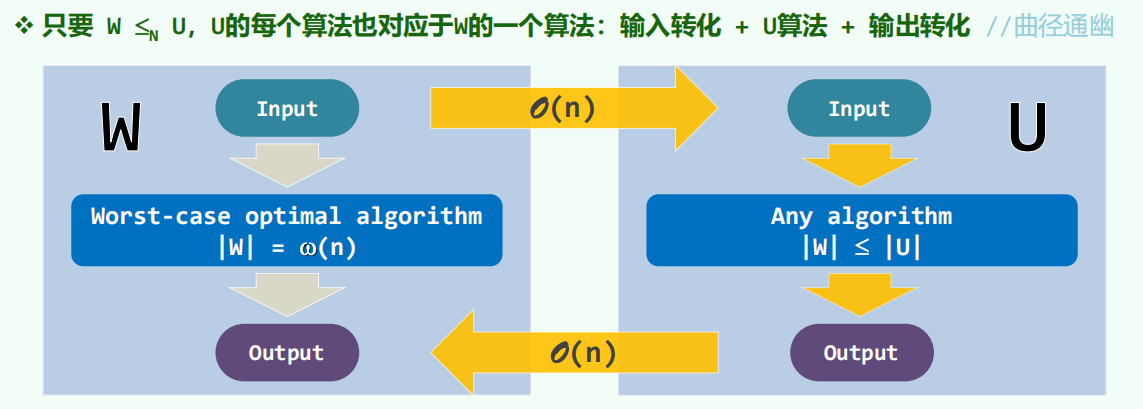
sorting<=Huffman:sorting 的每个输入可以直接理解为 Huffman 的每个输入 O (1),Huffman 算法输出编码树,层次遍历 O (n) 可以得到有序序列
Huffman>=sorting
sorting<=RBM
sorting 的输入直接转化为 x 轴上的 n 个红点 O (n),加上 y 轴的 n 个有序蓝点可以得到 RBM 输入。RBM 的输出一次遍历可以得到 sorting 输出。