DSA - 哈希表
复习期末。
我真他妈爱死这个世界了都给我去死吧。
夏日重现真好看!

测试一下播放器
词典
维护键值对。
词典 ADT:get,remove,put
空间从 R 到 M 的不完全映射。
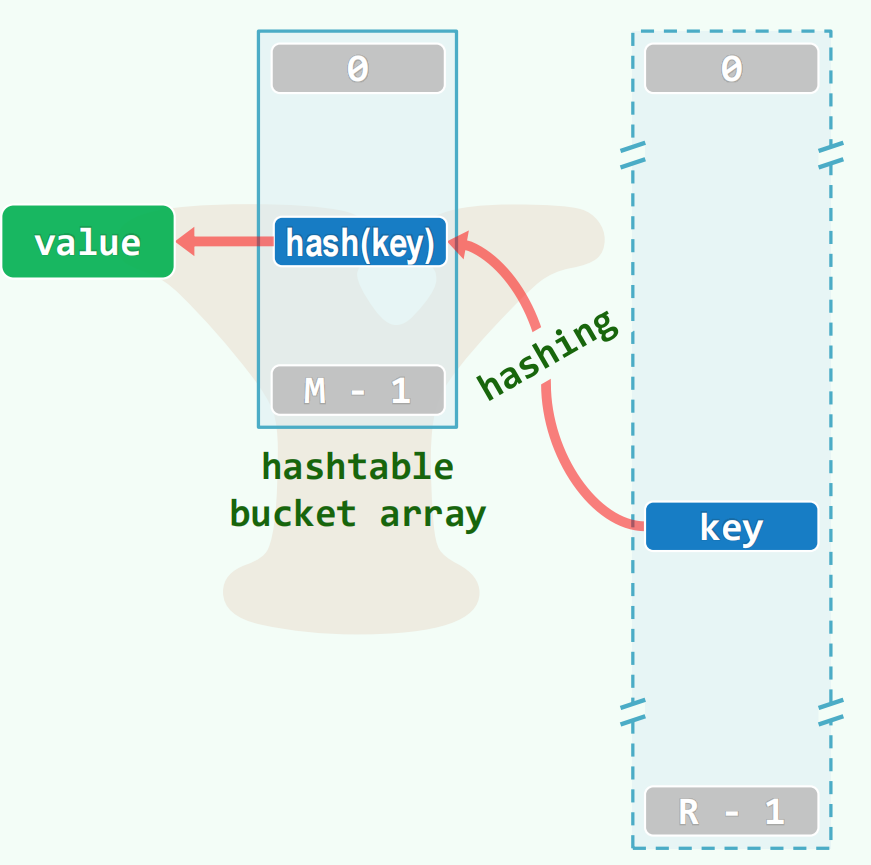
装填因子 $\lambda = N / M$,N 是实际使用的键。装填因子越低,空间使用率越低,冲突越轻
散列函数
理想的散列函数:同一键总是被映射到同一地址,尽可能高效率且充分利用整个散列空间。每个键映射到散列表每个桶的概率尽可能相同。
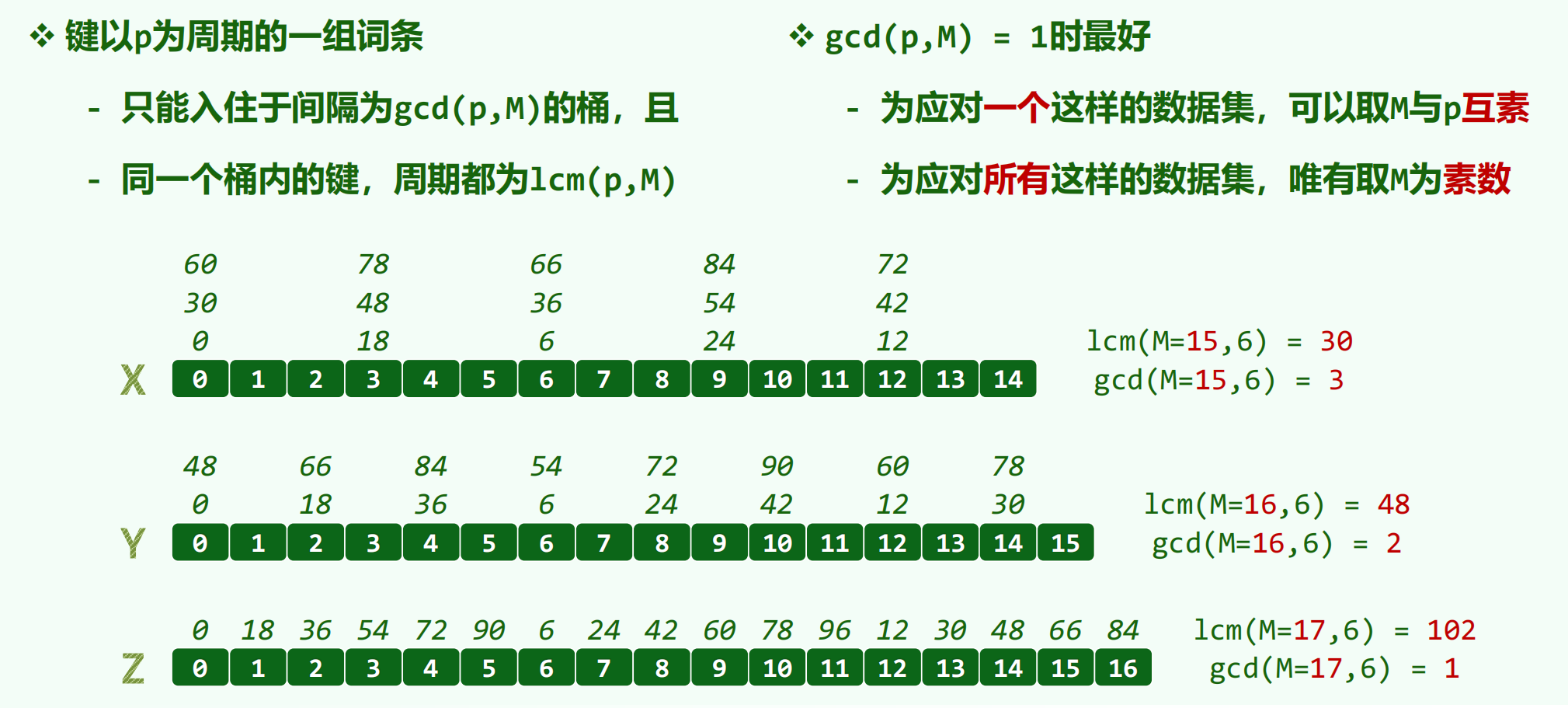
除余法:hash (key)=key% M
M 为素数时散列分布更加均匀
简单的使用除余法导致初级聚集:连续的键被映射到相邻的位置导致形成连续的大区块,导致原本 O (1) 的查找、插入退化
二级聚集:两个键被散列函数映射到了同一个桶,一些排解策略会导致后序探测序列完全一致。
MAD 法:hash (key)=(a * key + b)% M,避免了连续的键被映射到连续位置
更多散列函数:抽取 key 中的某几位;取 key2 的中间若干位;折叠法、把 key 分割各段做和;巴啦巴啦
优秀的字符串哈希函数:
1 | 0001 static Rank hashCode( char s[] ) { //多项式散列码 |
完全不同的字符串可能被映射到同一个桶。
冲突排解策略
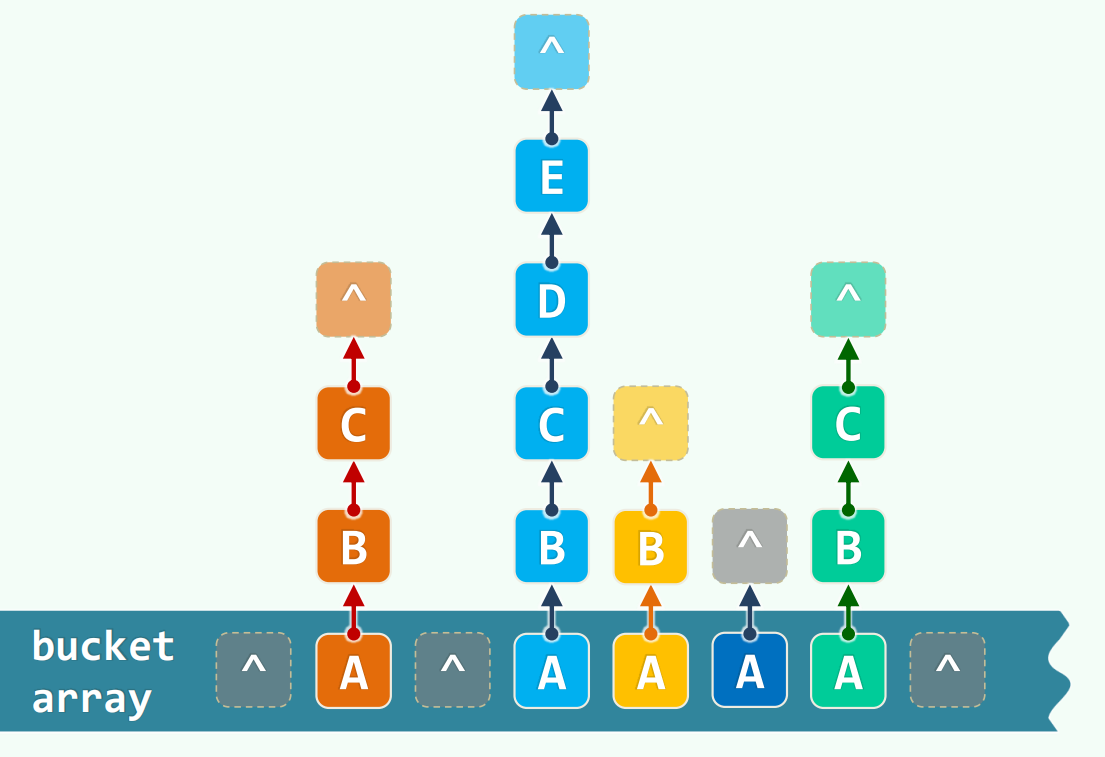
开放散列:
独立链:每个桶拥有一个列表存放同义词
任意多次冲突都可以解决,但是空间差而且难以发挥缓存作用。
封闭散列:散列表物理空间相对固定,冲突在内部解决。
为每一组同义词预备若干个备用桶,形成试探链;查找算法沿试探链逐个检视下一个桶单元直到命中成功,或抵达空桶为失败。

试探策略
线性试探:放不下就放后面一个

rk(x)=(hash(x)+k)%M
聚集严重:控制装填因子
试探长度恰好为 k 的概率为几何分布:$P (p = k)=\lambda ^{k-1} \cdot (1-\lambda),E (p)=1/(1-\lambda)$,控制装填因子 < 50% 使得期望的试探长度 = O (1)
插入删除:
懒删除:为每个桶增加标记 used 标记是否使用过。
每个哈希桶状态只有三种:
$used [k]==false:$ 从未使用;
$used [k]==true&&ht [k]==nullptr:$ 已使用过后被删除(墓碑),插入视为总是匹配的空桶,查找和删除视为必然不匹配的非空桶。
$used [k]==true&&ht [k]!=nullptr:$ 已使用过未被删除
删除:_s 是查找中遇到的第一个故居,_r 是遇到的第一个空宅或目标
1 | 0001 template <typename K, typename V> bool Hashtable<K,V>::remove( K k ) { |
查找:
1 | 0001 template <typename K, typename V> Entry<K,V>* Hashtable<K,V>::get( K k ) { |
插入需要先查找,然后把新元素插入在_s 位置。注意重新散列。
1 | 0001 template <typename K, typename V> bool Hashtable<K,V>::put( K k, V v ) { |
重散列就是把原来哈希桶每个真正存在的词条都拿出来重新放到一个新桶里。可以释放原来大量存在的 used 真而 ht 为空的僵尸。如果僵尸大量存在可能会使得重散列反而缩小容量。
1 | 0001 template <typename K, typename V> void Hashtable<K,V>::rehash() { //重散列 |
更好的试探策略:
平方试探:

rk(x)=(hash(x)+k2) mod M
缓解了聚集现象,减少首次聚集。
二次剩余:若 M 为合数,二次剩余可能少于 M/2;M 为素数,二次剩余恰好 M/2 且被前 M/2 项取尽。(向上取整)

双向平方试探:
交替沿两个方向试探,按平方确定距离。

rk(x)=(hash(x)-(-1)k*(⌈k/2⌉)2) mod M
得到长达 M 的无冲突试探链。
二次剩余:
费马双平方定理等价引理:
M = 4k + 3 的素数,-1 是模 M 二次非剩余;M = 4k + 1 的素数,-1 是模 M 的二次剩余
若发生冲突
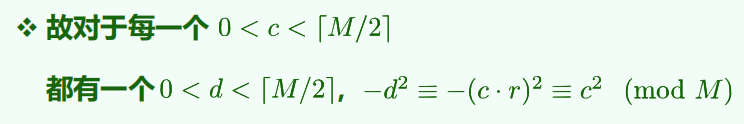
等价于 r 平方和 - 1 同余于 M
M = 4k + 3 时,方程无解,不会冲突;M = 4k + 1,方程一定有解,且对于每一个 c 都有 d 对应,完全冲突
散列应用
桶排序:
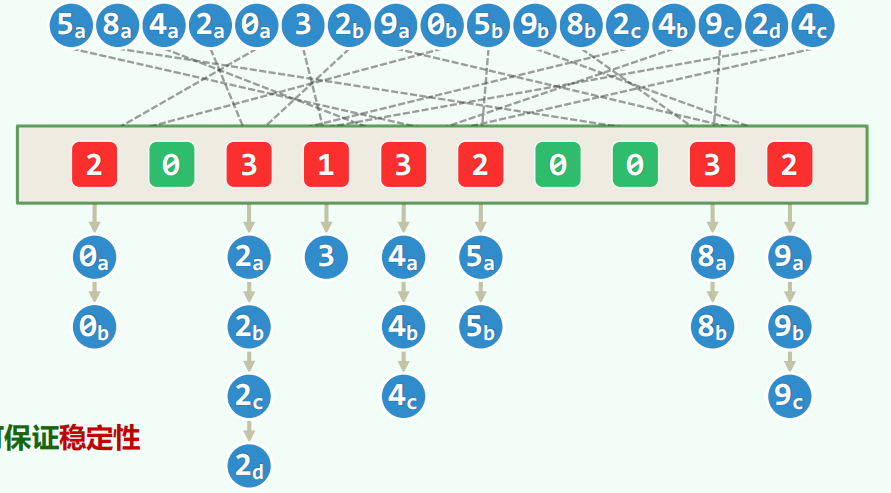
开放散列,独立链。可以保证稳定性。小范围存在大量数据,可以直接映射,取出的时候依次序取出即可排序。
MaxGap 问题:任意 n 个点讲实轴分为 n-1 个区间,哪一段最长?

先找到全局最左最右点,lo 和 hi;将有效范围均分为 n-1 段,但是 n 个桶(维护左闭右开区间,n-1 桶只有 hi 元素),通过简单的除法将每个点归入各自的桶。在每个桶中动态记录最左最右点。最后遍历一遍,算全体非空桶的后一个最小值和前一个最大值之差,得到最大距离。
正确性:抽屉原理保证一定有空桶。数据集的最大值不小于平均值。桶内点的距离小于平均值,于是一定不能成为 MaxGap;MaxGap 一定在非空桶之间取到
词典序:低位优先排序,依次按每一位做一遍桶排序。
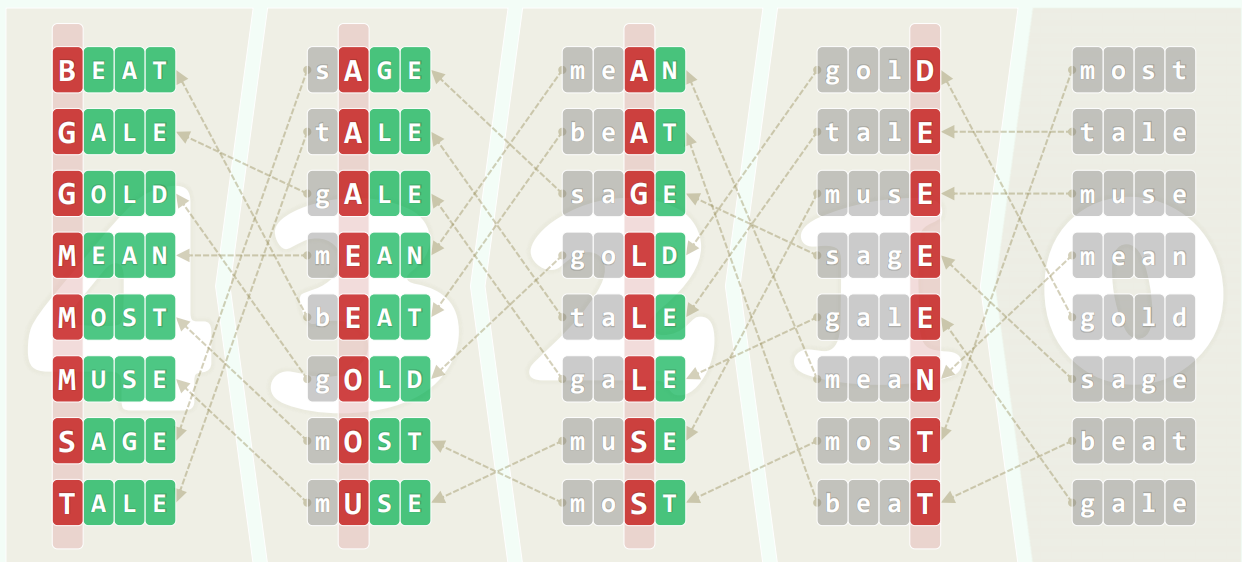
正确性:归纳假设,前 i 趟排序后低 i 位有序。考查第 i + 1 趟的排序。视第 i + 1 位:不同:即使此前逆序现在也有序了;相同:得益于稳定性,保持原序。
时间:O (dn)=O (n)。空间:O (M)。
二进制无符号整数基数排序。
出于简化实际没有使用哈希桶。
1 | 0001 using U = uint32_t; //约定:类型T或就是U,或可转换为U,并依此定序 |
按照从低到高位的顺序,从链表头考查到尾,把所有当前位为 1 的按照原来顺序放到尾部,保证稳定性。
由此实现线性的排序算法:基数排序
用 O (dn) 的时间将 n 个整数转换为 n 进制形式,x=(xd,…,x1),d≈logn(M)
开辟 n 个分桶,考查每一位的时候需要倒出来重排一遍。排序时间 = d*(n + n)=O (n),突破基于比较的时间复杂度。
计数排序:
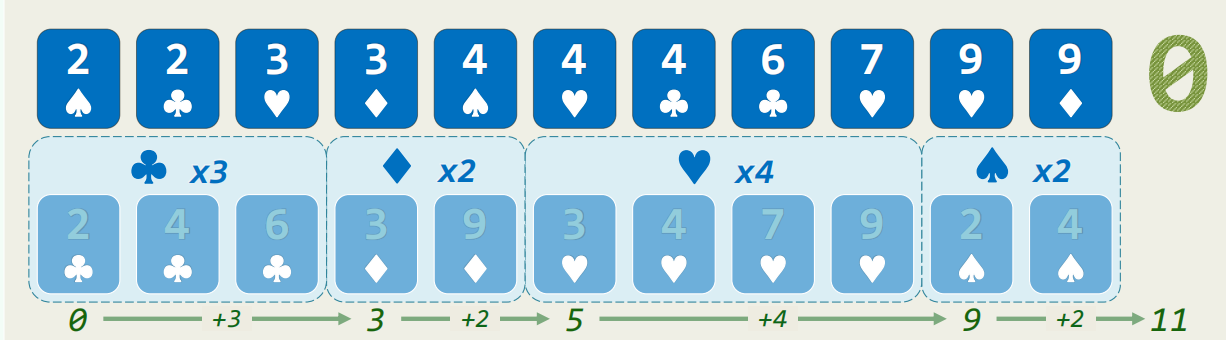
设已经按照点数排序,需稳定的按照花色排序。
O (n) 时间统计出各种花色数量。O (m) 时间扫描每个桶算前缀和,得到各套花色所处秩区间。O (n) 扫描每一张牌,对应桶计数减一得到最终在有序序列中的秩。