DSA 问题集第三章
Typora 自动上传图片把我顺序全弄乱了,索性重做了一个。
纯浪费时间来的。

列表

如果前后次序未知,可以固定一个指针,另一个指针同时向前向后走,同时统计两个距离,谁先遇到另一个指针就输出那个距离。

先跑到区间右端点,从右往左 p = p->pred 拷贝。空间性能基本不变,时间渐进依然 O (n) 但是常数变大。
1 | 0001 template <typename T> //依据蓝本列表的区间,复制出当前列表 |

设置两个指针 p = head,q = head->succ。p,q 同步移动,每次删除 p,p = q,q = q->succ,直到抵达 tail

1 | 0001 template <typename T> //在无序列表区间(h,t)内,找到等于e的最靠前者:h < t |
1 | 0001 template <typename T> void List<T>::dedup() { //O(n^2) |
a) 最好情况全等,每次循环都要以 O (1) 时间找到前面的重复元素(因为就是第一个),O (1) 删除前一个相同的元素,循环 n 次 O (n)
b) 因为删除操作不会产生移动
c) 刚开始循环就会被预设哨兵拦下
d) 这个算法不变性在于维护了无重复元素的前缀。改成维护无重复后缀,需要从尾部实质节点开始,找区间 (p,tail) 里面的和当前相同的元素。
e) 需要手动调整指针位置,如果要删除 p 的时候备份 p->succ 再删除 p,然后跳转到原先的 p->succ;否则跳转 succ
f) 空表,单表,全重复,全不重复,重复在表头 / 尾,交错重复

1 | void operator()(T& data) { |
1 | void operator()(T& data) { |

1 | 0001 template <typename T> void List<T>::uniquify() { //成批剔除重复元素,效率更高 |
a) 节省多余操作
b) 只用一个指针,每次判断这个指针和它的后继是否相同,相同就删后继不相同就不删。
1 | 0001 template <typename T> LNP<T> List<T>::getMax( LNP<T> h, LNP<T> t ) { //2 <= t - h |
1 | 0001 template <typename T> void List<T>::selectionSort( LNP<T> h, LNP<T> t ) { |
c) 修改 < 为 <=
d) n-1 次,完全相同的列表每次在后面遇到相同元素需要更新 x
选择排序


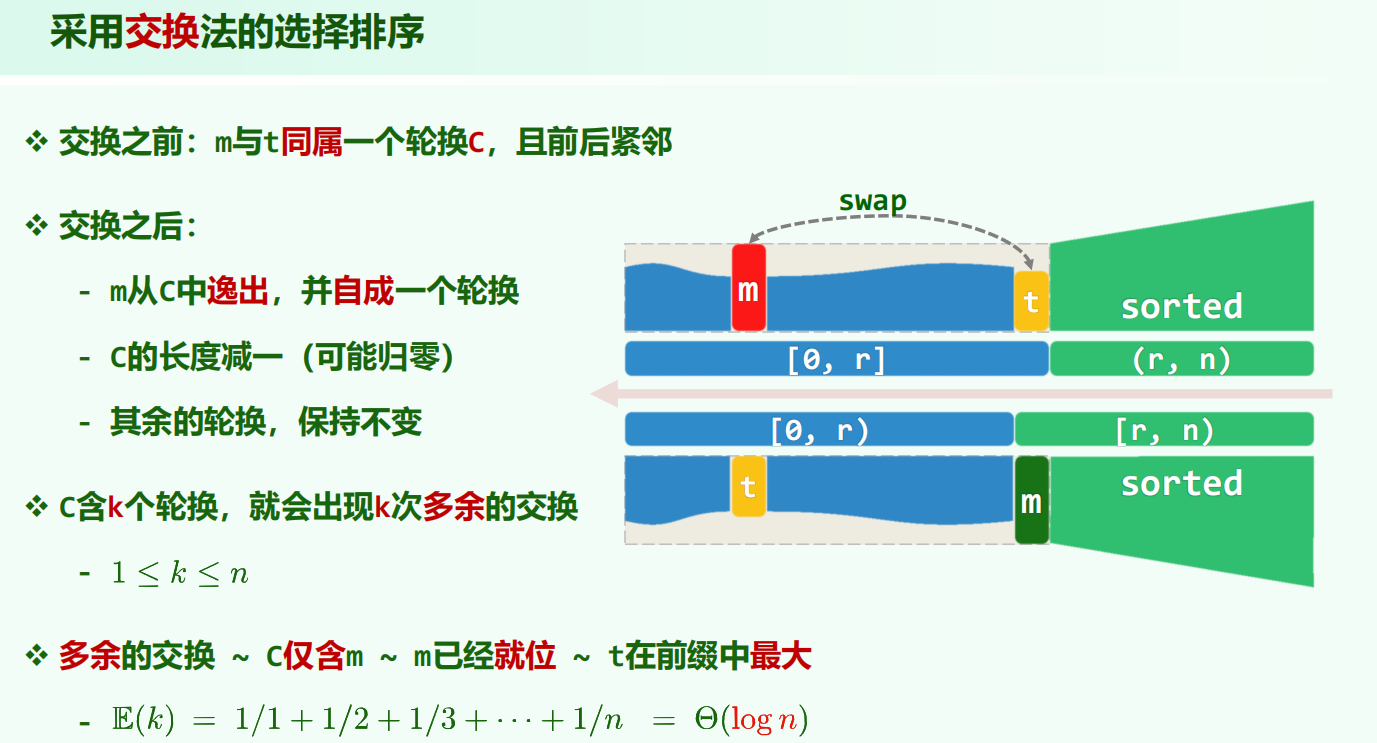
a) m 指向的位置是无序前缀的末尾,所以 m 和 x 同属一个轮换且相邻
b) m 显然,原先指向 m 所在位置的元素现在指向位置不变,但是指向了 x,而 x 指向下一个元素,相当于跳过了 m,所以当前轮换所缩减一个单位。
c) 对于长度为 L 的环,需要交换 L-1 才能让所有人都就位,此时最后一个人一定在正确的位置上,这就会产生多余的交换。所以 k 个环恰好对应 k 个多余交换。
d)e)ppt
f) 多余交换次数 = 轮换的个数

c) 错。[3,2,1] 一共只有一次原地移动但是两个环
e) 对。在前 r 个元素中把最大的抽走,剩下的相对位置不变,也就是说不改变随机性。依然调和级数求和。
插入排序
始终维护前缀 S 有序。反复针对 e = A [r],在 S 中查找适当位置插入 e。
哨兵可以支持头插尾插,不需要多余补丁代码。
1 | 0001 template <typename T> void List<T>::insertionSort( LNP<T> h, LNP<T> t ) { |
对输入敏感,最好 O (n)(每次 search 都是直接遇到比自己小的人),最坏 O (n2) 的在线算法
a)1/n!
b) 依然不改变局部随机性,调和级数之和 ln (n)
c) 处理第 k 个元素的时候,前 k-1 个元素已经有序,平均来看需要查找跳跃 k / 2 次,高斯和。
$\frac {n (n + 1)}{4}$ 依然 O (n2)
便于统计,把逆序对算作后者的。
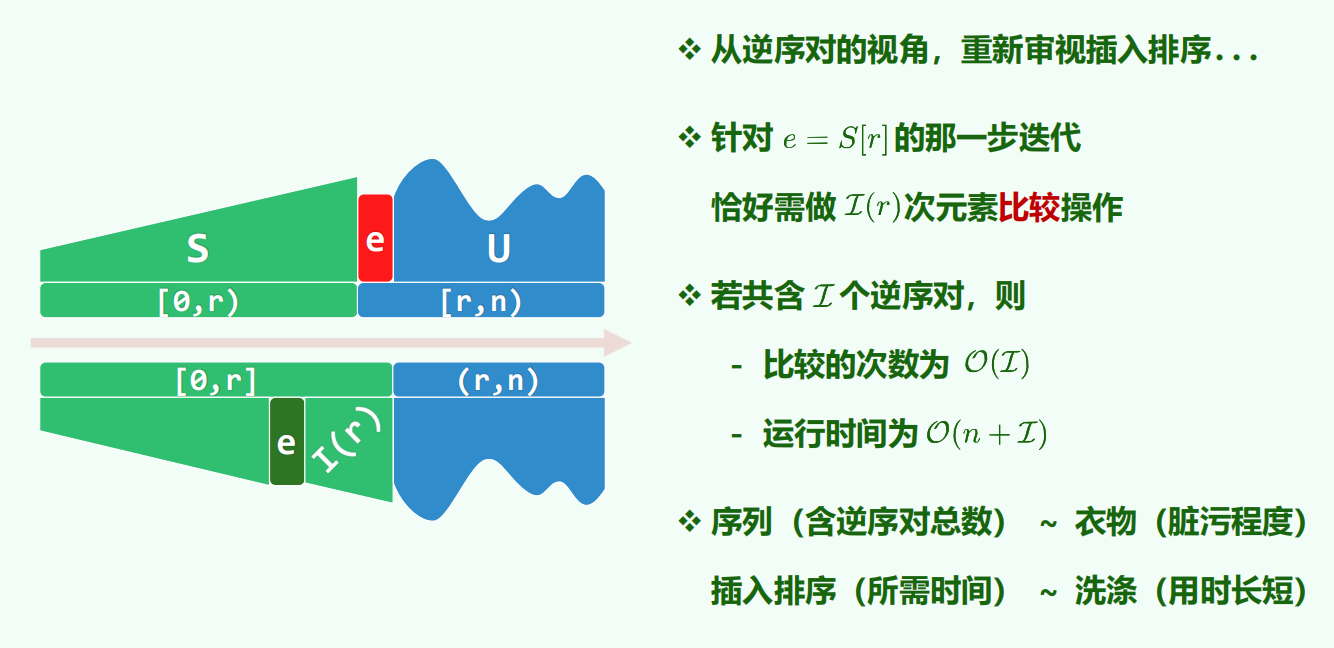
在插入排序中把未排序的元素 e 插入前缀中,需要从右往左挨个和前面的元素比对大小,只要前面的元素比自己大就往前走,比对次数就是 e 的逆序对
于是运行时间是 O (n + I),n 是必须付出的、所有元素都访问一遍花费的时间,I 是总的逆序对数量。

b) 一共有 $C^2_n$ 对,每一对成为逆序对的可能都是 1 / 2,因为数学期望似乎具有线性性质所以就是 $\frac {n (n + 1)}{4}$ 对
归并排序
二路归并
1 | 0001 template <typename T> //归并:(h,y) + [y,t) |

c)$T(n)=T(\lambda n)+T((1-\lambda)n)+O(n),T(n)=O(nlogn)$
d) 插入排序